
Gaussian mixture model (GMM) is a probability model for a mixture of several Gaussian distributions with possibly different mean and variance.
For example, we can model the 100m race time of all grade 12 students in a high school as two normal distributions: one for female students and one for male students. It is reasonable to expect two groups have different mean and may different variance.
When to use Gaussian mixture model?
1. Data has more than one clusters.
In the following picture, the left one models the data with one normal distribution; the right one models the data by two normal distribution, Gaussian mixture model. Obviously, the right one better describes the data.
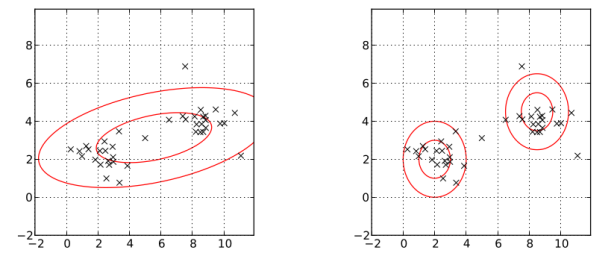
2. Each cluster is theoretically normally distributed.
Theory of Gaussian Mixture Model
1. Gaussian distribution in 1 dimension
Since there are several Gaussian distributions in the GMM. We assign an index to each Gaussian distribution:  for
for  where K is the number of clusters. For a given mean
where K is the number of clusters. For a given mean  and variance
and variance  , the probability density function is
, the probability density function is
![\[p_k(x|\mu_k,\sigma_k) = \frac{1}{\sigma_k\sqrt{2\pi}}exp\left(-\frac{(x-\mu_k)^2}{2\sigma_k^2}\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-7b3556434400e8b02f617b9229074736_l3.png "Rendered by QuickLaTeX.com")
Above
 is not the mathematical conditional expectation, but a statistical way of saying we know true parameters
is not the mathematical conditional expectation, but a statistical way of saying we know true parameters  in advance.
in advance.
2. Gaussian mixture model in 1 dimension
The probability density function of GMM is the weighted average of several Gaussian densities:
![\[p(x|\mu_k,\sigma_k, k=1,2,...,K) = \sum_{k=1}^K w_k \cdot p_k(x|\mu_k,\sigma_k ),\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-43a9821781ab30977d08dc18bed86dcd_l3.png "Rendered by QuickLaTeX.com")
where
![w_k \in [0,1]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-18b44b3c46cfe2fd81861b8978a60d70_l3.png "Rendered by QuickLaTeX.com") satisfies
satisfies ![\[\sum_{k=1}^K w_k = 1\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-1cbe2e8d5a2ce1f1fcaef3e32fe7c455_l3.png "Rendered by QuickLaTeX.com")
Plug in the Gaussian density,
![\[p(x) = \sum_{k=1}^K w_k \frac{1}{\sigma_k\sqrt{2\pi}}exp\left(-\frac{(x-\mu_k)^2}{2\sigma_k^2}\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-a657f7bc6c42e9486be0ba6c7a0cf787_l3.png "Rendered by QuickLaTeX.com")
Note that this is a density function because its integral on  is 1.
is 1.
3. Gaussian mixture model in n-dimension
Let  be an n-dimension multivariate Gaussian random variable with mean vector
be an n-dimension multivariate Gaussian random variable with mean vector and covariance matrix
and covariance matrix  . Then the probability density function is
. Then the probability density function is
![\[p_k(x|\mathbf{\mu_k} , \Sigma_k ) = \frac{1}{\sqrt{(2\pi)^K|\Sigma_k|}}exp\left(-\frac{1}{2}(x-\mathbf{\mu}_k)^T\Sigma_k^{-1}(x-\mathbf{\mu}_k )\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-fee79f6153c78831596c00886de0bb7f_l3.png "Rendered by QuickLaTeX.com")
Then, the probability density function of GMM, which is the weighted average of serveral multivariate Gaussian density, is
![\[p(x) = \sum_{k=1}^K w_k \frac{1}{\sqrt{(2\pi)^K|\Sigma_k|}}exp\left(-\frac{1}{2}(x-\mathbf{\mu}_k)^T\Sigma_k^{-1}(x-\mathbf{\mu}_k )\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-cc5be764062ddb791b6882bc4e93a1f4_l3.png "Rendered by QuickLaTeX.com")
with
Training the Model
Suppose that we know the number of clusters  a priori. (The choice of relies on statistician’s experience.) Then, we can use Expectation Maximization (EM) algorithm to find the parameters
a priori. (The choice of relies on statistician’s experience.) Then, we can use Expectation Maximization (EM) algorithm to find the parameters  and
and  or
or  for multi-dimensional model. Let be the number of clusters, and
for multi-dimensional model. Let be the number of clusters, and  be the number of samples.
be the number of samples.
Step 1: Initialize
- Randomly choose samples and set them to be the group mean. For example, in the case of
 ,
,  ,
,  . (note that this is also valid for multi-dimensional case)
. (note that this is also valid for multi-dimensional case) - Set all variances (resp. covariance matrices) to be the same value: sample variance (resp. sample covariance matrix). Namely,
where![\[\hat{\sigma_k}^2 = \frac{1}{N}\sum_i^N(x_i-\bar{x})^2,\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-19025e84c2b88d0c995e301952199ca8_l3.png "Rendered by QuickLaTeX.com")
 .
. - Set all weights equal to
 , i.e.,
, i.e., ![\[\hat{w_k} = \frac{1}{K}.\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-0127cfd21c1f27c80c7e60c4e36edbb1_l3.png "Rendered by QuickLaTeX.com")
Step 2: Expectation
We compute the probability that a sample  belongs to cluster
belongs to cluster  .
.
![\[\begin{aligned} \gamma_{nk} = &~ \mathbf{P}(x_n \in C_k|x_n, \hat{w_k}, \hat{\mu_k},\hat{\sigma_k} ) \\ = &~ \frac{\hat{w_k}p_k(x_n|\hat{\mu_k},\hat{\sigma_k})}{\sum_{j=1}^K \hat{w_j}p_j(x_n|\hat{\mu_j},\hat{\sigma_j}) } \end{aligned} \]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-9061aaabea11b55f164405f44bb9f7fa_l3.png "Rendered by QuickLaTeX.com")
Step 3: Maximization
Update parameters then go back to step 2 until converge
![\[\hat{w_k} = \frac{\sum_{n=1}^N\gamma_{nk}}{N}\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-2029d49cb4111873a88ee29459bdb4fa_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\mu_k} = \frac{\sum_{n=1}^N\gamma_{nk}x_i}{ \sum_{n=1}^N\gamma_{nk} }\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-e919444d875e3723786da4b77f4bbd6c_l3.png "Rendered by QuickLaTeX.com")
resp.![\[\hat{\sigma_k} = \frac{\sum_{n=1}^N\gamma_{nk}(x_n-\hat{\mu_k} )^2}{ \sum_{n=1}^N\gamma_{nk} }\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-d67e2738e34303acd3a6c5572cecf3fd_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\Sigma_k} = \frac{\sum_{n=1}^N\gamma_{nk}(x_n-\hat{\mu_k} )(x_n-\hat{\mu_k} )^T }{ \sum_{n=1}^N\gamma_{nk} }\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-5e899bee111b8a4c25f9e0629a6aacec_l3.png "Rendered by QuickLaTeX.com")
 and strike
and strike ![\[C_E - P_E = S_0 - Ke^{-rT},\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-003d36a4381615a4a8a6bcd91633509a_l3.png "Rendered by QuickLaTeX.com")
 is the price of
is the price of  is the price of the European put option,
is the price of the European put option,  is the price of the
is the price of the  .
. can be seen as a forward contract with maturity
can be seen as a forward contract with maturity ![\[(S_T-K)^+ + (K_T-S)^+ = S_T - K\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-600c329621a498f24fd142f948b7bb87_l3.png "Rendered by QuickLaTeX.com")
![\[\begin{aligned}& P(0,T)E[(S_T-K)^+] + P(0,T)E[(K-S_T)^+] \\ & = P(0,T)E[S_T - K],\end{aligned}\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-5eb6438c9f251d8cb7314f091d271dbf_l3.png "Rendered by QuickLaTeX.com")
 is the discount factor from
is the discount factor from  , and
, and  is the expectation under the risk neutral measure. Above equation is equivalent to the European put-call parity formula.
is the expectation under the risk neutral measure. Above equation is equivalent to the European put-call parity formula. . If we exercise the option at time
. If we exercise the option at time  , then we have
, then we have  cash position and
cash position and  at this time. Then, at time
at this time. Then, at time  . That is
. That is![\[C_E = C_A\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-ef54a410567895cf99f23891f2fa60cd_l3.png "Rendered by QuickLaTeX.com")
![\[S_0 - K \leq C_A-P_A \leq S_0 - Ke^{-rT}\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-9622a321de5ca93455cf7c501e98e96e_l3.png "Rendered by QuickLaTeX.com")
 .
. ![t \in [0,T]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-e88dbf1b3766ac724ea7ac1993e27abb_l3.png "Rendered by QuickLaTeX.com") .
.  for the option part and
for the option part and  for the asset and cash part. The total value of the portfolio is
for the asset and cash part. The total value of the portfolio is  .
. ![\[C_A - P_A - S_0 + K \geq 0\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-777e90a48cc26e26872082fe5661d0c5_l3.png "Rendered by QuickLaTeX.com")
![\[\begin{aligned} &~ C_A - P_A \\ = &~ C_E - P_E + P_E - P_A \\ = &~ S_0 - K e^{-rT} + P_E - P_A \\ \leq &~ S_0 - Ke^{-rT}\end{aligned}\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-fe1a798b995e50876a2ad42b955381b4_l3.png "Rendered by QuickLaTeX.com")
![\[\textnormal{d}S_t = S_t(r \textnormal{d} t + \sigma \textnormal{d} W_t)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-3a94c20525f6a4b7afa9ae31effad08b_l3.png "Rendered by QuickLaTeX.com")
 . Let
. Let ![\[A_T = \frac{1}{T}\int_0^T S_u \textnormal{d} u\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-065c7c1d22d4363cb9c47c1f5af4b544_l3.png "Rendered by QuickLaTeX.com")
 and European vanilla call option has the payoff
and European vanilla call option has the payoff ![\[\begin{aligned} &~ \mathbb{E}[e^{-rT}(A_T-K)^+] \\= &~ \mathbb{E}[e^{-rT}(\frac{1}{T}\int_0^T S_u \textnormal{d} u -K)^+] \\\leq & ~ \mathbb{E}[e^{-rT}\frac{1}{T}\int_0^T (S_u-K)^+ \textnormal{d} u] \\= &~ \frac{1}{T}\int_0^T \mathbb{E}[e^{-rT} (S_u-K)^+ ] \textnormal{d} u \\\leq &~ \frac{1}{T}\int_0^T \mathbb{E}[e^{-ru} (S_u-K)^+ ] \textnormal{d} u \\\leq &~ \frac{1}{T}\int_0^T \mathbb{E}[e^{-rT} (S_T-K)^+ ] \textnormal{d} u \\ = &~ \mathbb{E}[e^{-rT} (S_T-K)^+ ] \\ \end{aligned}\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-5cf23b380e772edddabfc8ff197e5364_l3.png "Rendered by QuickLaTeX.com")