
Feynman-Kac formula connects the solution to a SDE to the solution of a PDE. For example, the Black-Scholes formula is an application of Feynman-Kac.
Let  satisfies the following SDE driven by standard Brownian Motion:
satisfies the following SDE driven by standard Brownian Motion:
![\[\textnormal{d}X_u = \beta(u,X_u)\textnormal{d}u + \gamma(u,X_u\textnormal{d}W_u).\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-da0988752a9bb3767fe65702a0a5a735_l3.png "Rendered by QuickLaTeX.com")
Let  be a Borel measurable function, and
be a Borel measurable function, and ![t \in [0,T]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-e88dbf1b3766ac724ea7ac1993e27abb_l3.png "Rendered by QuickLaTeX.com") . Define
. Define
![\[\begin{aligned} g(t,x) := \mathbf{E} [&\int_t^Te^{-\int_t^TV(\tau,X_{\tau})\textnormal{d}\tau}f(r,X_r)\textnormal{d}r \\ &+e^{-\int_t^TV(\tau,X_{\tau})}h(X_T)|X_t = x ] \end{aligned}.\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-ce949eee9441cd7cb71600b656d22116_l3.png "Rendered by QuickLaTeX.com")
Then,  satisfies PDE
satisfies PDE
![\[g_t + \beta g_x + \frac{1}{2}\gamma^2 g_{xx} - Vg + f = 0.\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-d3cfc1519f570a492a74e22dc73c9119_l3.png "Rendered by QuickLaTeX.com")
Proof.
To get an idea of how this formula is proved, we start with a base case. The general case is proved by the same manner with a little more complicated calculation.
Suppose  .
.
Let  be the natural filtration associated with the standard Brownian Motion in the SDE. By the Markov property of the solution to SDE, we have
be the natural filtration associated with the standard Brownian Motion in the SDE. By the Markov property of the solution to SDE, we have ![\forall s \in [0,T]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-bc5e603d94a7d42d194181ded5b2009c_l3.png "Rendered by QuickLaTeX.com") ,
,
![\[\mathbf{E}[h(X_T)|\mathcal{F}(s)] = \mathbf{E}[h(X_T)|\sigma(X_s)] = g(s,X_s).\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-4fbd7748e0d234db7a671a155df98f4f_l3.png "Rendered by QuickLaTeX.com")
Then, for 
![\[\begin{aligned} \mathbf{E}[g(t,X_t)|\mathcal{F}(s)] & = \mathbf{E}[ \mathbf{E}[h(X_T)| \mathcal{F}(t) ] |\mathcal{F}(s)] \\ &= \mathbf{E}[h(X_T)|\mathcal{F}(s)] = g(s,X_s) \end{aligned}\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-58aa72aa009bf26d9daa3bc7bf8f2b72_l3.png "Rendered by QuickLaTeX.com")
Hence,  is a martingale.
is a martingale.
Then, we apply Ito’s formula to . Its drift term should be zero because it is a martingale. This leads to the Feynman-Kac PDE.
![\[\begin{aligned} \textnormal{d}g(t,X_t) & = g_t\textnormal{d}t + g_x \textnormal{d} x + \frac{1}{2}g_{xx} \textnormal{d} X \textnormal{d} X \\ & = [g_t+\beta g_x + \frac{1}{2}\gamma^2 g_{xx}] \textnormal{d} t + \gamma g_x \textnormal{d} W\end{aligned}.\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-91595ea304137e12671716f319367ebf_l3.png "Rendered by QuickLaTeX.com")
By setting the  term equal to
term equal to  , we get the PDE:
, we get the PDE:
![\[g_t+\beta g_x + \frac{1}{2}\gamma^2 g_{xx} = 0.\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-fc69db4e6d7a076810e403324178dec6_l3.png "Rendered by QuickLaTeX.com")
For the general case, we only need to factor out the  integral and make the integral inside the expectation only contains
integral and make the integral inside the expectation only contains  term. We will get
term. We will get  is a martingale with defined as:
is a martingale with defined as:
![\[G(t,x):= e^{-\int_0^tV(\tau,X_{\tau})\textnormal{d}\tau}(g(t,x)+\int_0^t e^{-\int_t^rV (\tau,X_{\tau})\textnormal{d}\tau } f(r,X_r) \textnormal{d}r)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-7140822f6fc79e87bee1cde0267ac87f_l3.png "Rendered by QuickLaTeX.com")
Similarly, by applying Ito’s formula to above martingale and setting the drift term equal to 0, we will get the result.
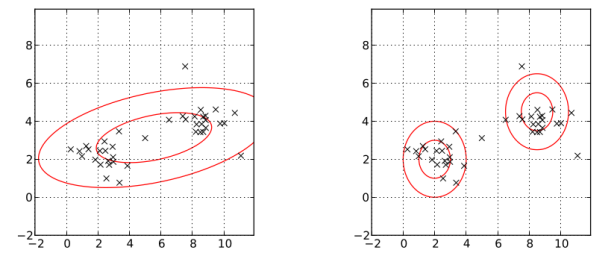
 for
for  where K is the number of clusters. For a given mean
where K is the number of clusters. For a given mean  and variance
and variance  , the probability density function is
, the probability density function is ![\[p_k(x|\mu_k,\sigma_k) = \frac{1}{\sigma_k\sqrt{2\pi}}exp\left(-\frac{(x-\mu_k)^2}{2\sigma_k^2}\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-7b3556434400e8b02f617b9229074736_l3.png "Rendered by QuickLaTeX.com")
 is not the mathematical conditional expectation, but a statistical way of saying we know true parameters
is not the mathematical conditional expectation, but a statistical way of saying we know true parameters  in advance.
in advance.
![\[p(x|\mu_k,\sigma_k, k=1,2,...,K) = \sum_{k=1}^K w_k \cdot p_k(x|\mu_k,\sigma_k ),\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-43a9821781ab30977d08dc18bed86dcd_l3.png "Rendered by QuickLaTeX.com")
![w_k \in [0,1]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-18b44b3c46cfe2fd81861b8978a60d70_l3.png "Rendered by QuickLaTeX.com") satisfies
satisfies![\[\sum_{k=1}^K w_k = 1\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-1cbe2e8d5a2ce1f1fcaef3e32fe7c455_l3.png "Rendered by QuickLaTeX.com")
![\[p(x) = \sum_{k=1}^K w_k \frac{1}{\sigma_k\sqrt{2\pi}}exp\left(-\frac{(x-\mu_k)^2}{2\sigma_k^2}\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-a657f7bc6c42e9486be0ba6c7a0cf787_l3.png "Rendered by QuickLaTeX.com")
 is 1.
is 1. be an n-dimension multivariate Gaussian random variable with mean vector
be an n-dimension multivariate Gaussian random variable with mean vector and covariance matrix
and covariance matrix  . Then the probability density function is
. Then the probability density function is ![\[p_k(x|\mathbf{\mu_k} , \Sigma_k ) = \frac{1}{\sqrt{(2\pi)^K|\Sigma_k|}}exp\left(-\frac{1}{2}(x-\mathbf{\mu}_k)^T\Sigma_k^{-1}(x-\mathbf{\mu}_k )\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-fee79f6153c78831596c00886de0bb7f_l3.png "Rendered by QuickLaTeX.com")
![\[p(x) = \sum_{k=1}^K w_k \frac{1}{\sqrt{(2\pi)^K|\Sigma_k|}}exp\left(-\frac{1}{2}(x-\mathbf{\mu}_k)^T\Sigma_k^{-1}(x-\mathbf{\mu}_k )\right)\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-cc5be764062ddb791b6882bc4e93a1f4_l3.png "Rendered by QuickLaTeX.com")
 a priori. (The choice of
a priori. (The choice of  and
and  or
or  for multi-dimensional model. Let
for multi-dimensional model. Let  be the number of samples.
be the number of samples. ,
,  ,
,  . (note that this is also valid for multi-dimensional case)
. (note that this is also valid for multi-dimensional case)![\[\hat{\sigma_k}^2 = \frac{1}{N}\sum_i^N(x_i-\bar{x})^2,\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-19025e84c2b88d0c995e301952199ca8_l3.png "Rendered by QuickLaTeX.com")
 .
. , i.e.,
, i.e., ![\[\hat{w_k} = \frac{1}{K}.\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-0127cfd21c1f27c80c7e60c4e36edbb1_l3.png "Rendered by QuickLaTeX.com")
 belongs to cluster
belongs to cluster  .
. ![\[\begin{aligned} \gamma_{nk} = &~ \mathbf{P}(x_n \in C_k|x_n, \hat{w_k}, \hat{\mu_k},\hat{\sigma_k} ) \\ = &~ \frac{\hat{w_k}p_k(x_n|\hat{\mu_k},\hat{\sigma_k})}{\sum_{j=1}^K \hat{w_j}p_j(x_n|\hat{\mu_j},\hat{\sigma_j}) } \end{aligned} \]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-9061aaabea11b55f164405f44bb9f7fa_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{w_k} = \frac{\sum_{n=1}^N\gamma_{nk}}{N}\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-2029d49cb4111873a88ee29459bdb4fa_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\mu_k} = \frac{\sum_{n=1}^N\gamma_{nk}x_i}{ \sum_{n=1}^N\gamma_{nk} }\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-e919444d875e3723786da4b77f4bbd6c_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\sigma_k} = \frac{\sum_{n=1}^N\gamma_{nk}(x_n-\hat{\mu_k} )^2}{ \sum_{n=1}^N\gamma_{nk} }\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-d67e2738e34303acd3a6c5572cecf3fd_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\Sigma_k} = \frac{\sum_{n=1}^N\gamma_{nk}(x_n-\hat{\mu_k} )(x_n-\hat{\mu_k} )^T }{ \sum_{n=1}^N\gamma_{nk} }\]](https://sisitang0.com/wp-content/ql-cache/quicklatex.com-5e899bee111b8a4c25f9e0629a6aacec_l3.png "Rendered by QuickLaTeX.com")
 be a filtered probability space. A càdlàg stochastic process (adapted to the filtered probability space) is called a semi-martingale if it can be represented as the sum of a local martingale and a process of locally bounded variation.
be a filtered probability space. A càdlàg stochastic process (adapted to the filtered probability space) is called a semi-martingale if it can be represented as the sum of a local martingale and a process of locally bounded variation. be continuous semi-martingales, and
be continuous semi-martingales, and  , be a
, be a  function.
function.  denotes the quadratic covariation of continuous semi-martingales
denotes the quadratic covariation of continuous semi-martingales  and
and  . Then,
. Then,  ,
,